SQL语法提示工具SQL Prompt使用教程:表没有聚簇索引(BP021)
SQL Prompt是一款实用的SQL语法提示工具。SQL Prompt根据数据库的对象名称、语法和代码片段自动进行检索,为用户提供合适的代码选择。自动脚本设置使代码简单易读--当开发者不大熟悉脚本时尤其有用。SQL Prompt安装即可使用,能大幅提高编码效率。此外,用户还可根据需要进行自定义,使之以预想的方式工作。
如果SQL Prompt提醒您注意没有聚集索引的表,请仔细调查其不存在的原因。确实很少有一个表可以在没有表的情况下更快地进行数据检索。
除少数例外,每个表都应具有聚集索引。但是,它们并非始终对性能至关重要。聚集索引的值取决于表的使用方式,查询的典型模式以及表的更新方式。对于表更重要的是它应该具有适当的主键。如果您不能解释避免在表上使用聚集索引的充分理由,那么拥有一个索引要安全得多。除非您确切知道该表的使用方式,否则很难找到充分的理由。
堆和SQL Server
堆是没有聚簇索引的表,在SQL Server中被视为表的顽皮姐妹,并且在过去,它们通常都能达到其声誉。例如,在以前的SQL Server版本中,无法重建索引。由于转发指针,表的插入和删除操作会增加查询响应时间。
创建堆时,各个记录没有任何逻辑顺序。因此,要查找特定记录,SQL Server将需要对行的引用(物理RID),或者需要全表扫描才能找到该记录。要获取该RID,查询必须使用非聚集索引。非聚集索引存储堆中每个记录的物理RID。
通过重复更新,您会因碎片而导致性能损失。如果堆需要进行碎片整理,这很好地表明应通过添加聚簇索引将其转换为表。
SQL Server中的聚集索引
关系理论中没有聚集索引之类的东西。但是,任何主要的RDBMS(例如SQL Server或Oracle)都将拥有它们。聚集索引在SQL Server中特别重要。从技术上讲,没有聚集索引的表不是表,而是“堆”。未索引的堆仅对我们几乎不需要读取的日志有效。一个索引良好的堆可以像表一样执行。
对于一个使用率很高的OLTP数据库系统来说,它发生了很多变化,并且进行了许多快速,简单的查询,因此聚集索引成为显而易见的选择。聚簇索引用于组织表,而非聚簇索引用于支持查询。聚集索引键应为“窄”,“唯一”,“静态”和“不断增加”(NUSE)。这样,我们的意思是所选列的各个行应占用尽可能少的存储空间,因为聚集索引也用于非聚集索引查找中。每行都必须是唯一的或尽可能接近。列中的值不应该更改。如果聚簇索引不断增加,这将有很大帮助,因此行以聚簇索引的升序排列。如果新行在聚簇索引键中始终具有较高的值,则无需在序列中插入行,只需在末尾添加即可。插入在存储中以逻辑顺序发生,并且将避免页面拆分。
尽管递增IDENTITY列通常作为密钥,但这并不总是最佳选择。例如,太多的交易数据是基于日期和时间的,因此date列成为更自然的选择,尤其是因为日期通常用于过滤数据时。但是,聚类索引的选择很大程度上取决于使用模式和需要快速插入的“热点”的出现。
不要混淆主键和聚集索引
主键是逻辑构造,聚簇索引是物理上存储数据的特殊方式。通常选择聚集索引来体现主键。通过为密钥指定聚簇索引,可以确定密钥的实现方式。主键很可能可以通过聚簇索引键最有效地实现,但不是必须的。
当您通常基于索引值唯一的主键选择行时(例如,基于值选择行时),聚集索引对于主键效果很好。它对于一系列主键值也很有效,因为表行在存储中将彼此相邻。可能一起查询的行存储在一起
一个表只能有一个聚集索引,因此您需要仔细选择。具有逻辑意义的候选键作为主键并不一定具有性能良好的聚集索引所需的特征。
比较堆和表的静态数据
聚集索引最适用于可能选择主要是单个值的查询,或者需要从不属于主键的列中返回数据的查询。如果类别列具有聚集索引,则它们对于通常在类别中选择未排序或已排序范围的查询非常有效。
如果总是通过非聚集索引访问数据,有时最好避免使用聚集索引。这通常是因为对堆中实际行的引用(RID或行标识符)可能小于聚集索引键。通常为几乎从未读取,必须快速写入且永不更新的日志表选择堆。
索引堆的另一个明显用途是将表中的数据很少进行增量更改,例如目录。没有“自然”顺序并经常更新的表有时也可以作为堆更好地工作。
为了说明这一点,我创建了一个包含业务目录的四百万行表,并将其存储在堆和表中。如果要重现测试,我已经为bigdirectory表提供了构建脚本和一个SQL Data Generator项目XML文件,以填充400万行(可以根据需要降低它)。它实际上是.sqlgen文件类型,但已重命名为.xml扩展名。您需要编辑DataSourceXML项目文件以提供正确的连接和数据库详细信息,然后将其另存为.sqlgen文件。
<DataSource version="4" type="LiveDatabaseSource"> <ServerName>MyServerName</ServerName> <DatabaseName>MyDatabase</DatabaseName> <Username /> <SavePassword>False</SavePassword> <Password /> <ScriptFolderLocation /> <MigrationsFolderLocation /> <IntegratedSecurity>True</IntegratedSecurity> </DataSource>
这两个表都给出了合适的覆盖索引:
CREATE NONCLUSTERED INDEX CountyBusinessTypeCovering
ON dbo.BigDirectory (county, BusinessType)
INCLUDE
(Name, Address1, Address2, town, city, Postcode, Region,
Leads, Phone, Fax, Website );
我们要从这400万行表BigDirectory及其邪恶的堆双胞胎HeapBigDirectory中提取埃塞克斯郡所有行的所有列,其业务范围以“R”开头。
DECLARE @bucket INT
SELECT --count of filtered result from heap
@bucket = Count(*)
FROM Heapbigdirectory
WHERE county = 'essex' AND businessType LIKE 'r%';
SELECT --count of filtered result from table
@bucket = Count(*)
FROM bigdirectory
WHERE county = 'essex' AND businessType LIKE 'r%';
SELECT --heap, get all columns
*
INTO #sometempTable
FROM Heapbigdirectory
WHERE county = 'essex' AND businessType LIKE 'r%';
SELECT --table, get all columns
*
INTO #othertempTable
FROM bigdirectory
WHERE county = 'essex' AND businessType LIKE 'r%';
DROP TABLE #sometempTable
DROP TABLE #othertempTable
我们使用SQL Prompt chk片段将其放入测试工具。
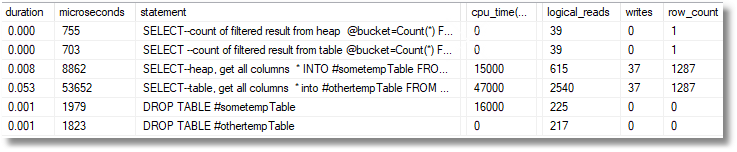
当堆设法在七分之一的时间内将数据写入临时表时,其性能优于表,尽管实际的行标识花费了相同的时间。当然,在此示例中,从理论上讲,该查询应该不需要去表以获取数据,因为可以从索引中获取结果。
因此,让我们从表中删除非聚集索引,然后在每个不再覆盖的堆上创建一个新索引。
CREATE NONCLUSTERED INDEX CountyBusinessType ON dbo.BigDirectory (county, BusinessType); CREATE NONCLUSTERED INDEX CountyBusinessType ON dbo.HeapBigDirectory (county, BusinessType);
我们使用仅支持过滤器的查询,而保留通过RID或聚集索引来完成数据收集
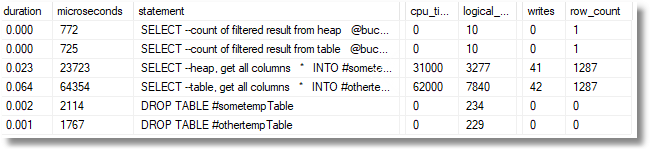
既然堆必须通过RID查找从行中获取数据,它的优点已经减少,但仍然比表快三倍。
总结
真正的代码味道不是缺少聚集索引,而是查询中引用的列上根本没有任何索引。如果您可以拥有一个具有Narrow,Unique,Static和Ever-Increating键的不错的聚集索引,那么您可以合理地确信该表可以处理使用非聚集索引列进行过滤的任何查询,尤其是当索引覆盖。
为了使某个堆在任何特定查询中的性能都更高,非聚集索引必须覆盖在JOIN或WHEREfilter子句中使用的所有列,并且该表本质上必须是静态的。
相关内容推荐:

 QQ交谈
QQ交谈 在线咨询
在线咨询


 渝公网安备
50010702500608号
渝公网安备
50010702500608号

 客服热线
客服热线