SQL Compare是一款比较和同步SQL Server数据库结构的工具。现有超过150,000的数据库管理员、开发人员和测试人员在使用它。当测试本地数据库,暂存或激活远程服务器的数据库时,SQL Compare将分配数据库的过程自动化。
点击下载SQL Compare试用版
您想使用SQL Compare或SQL Change Automation(SCA)创建或更新数据库,同时确保其数据符合您的期望。您希望避免每次都运行任何其他PowerShell脚本,并且希望将所有内容(包括数据)保持在源代码控制中。您只想让一切简单。Phil Factor通过MERGE从存储过程中生成脚本演示了它是如何完成的。
如果没有很多数据,或者只有几个需要一些静态数据的表,则可以使用SQL Compare或SCA轻松完成此操作,方法是添加一个部署后脚本,该脚本将作为同步。否则,它只是部署过程中要运行的一个额外脚本。
我们将使用上一篇文章将自定义部署脚本与SQL Compare或SQL Change Automation结合使用中描述的技术,该技术涉及运行一系列MERGE脚本以确保数据库具有所需的数据。为了创建这些MERGE脚本,我使用了PPP(相当强大的过程),我将在这里进行介绍。手工编写这些脚本很费力,尽管您几乎不需要重复创建脚本的繁琐工作,但是需要对它进行修改以响应相应表的更改。
有什么问题呢?
如果没有数据,那么重新设计数据库将很简单。无论我们拖延了繁琐的开发工作,当我们要部署到UAT,登台和生产时,在保持数据完整的同时部署架构更改的问题始终会困扰我们。在进行大量的重新设计之后,无论选择哪种方式创建数据库的新版本,我们总是冒着在处理现有数据时遇到困难的风险,尤其是在拆分,合并或重命名表的情况下。
尽管我一直主张在整个开发过程中测试您的数据迁移脚本,但有时您只需要一个带有某些描述的数据的工作系统,该数据是从源代码控制构建的。为此,我们有其他选择:
-
构建元数据并随后使用BCP导入数据(请参阅使用SQL Change Automation从头开始创建数据库)。
-
作为构建的一部分,在受影响的表中将数据从旧模式“迁移”到新表(在基于状态的数据库部署过程中处理棘手的数据迁移)
-
使用部署前和部署后脚本处理该问题,使DML活动与用于构建数据库的DDL保持牢固的距离。(将自定义部署脚本与SQL Compare或SQL Change Automation一起使用)
通常,我们仅从源进行一次构建,然后在开发和测试中将其与各种数据库副本同步。通常,现代关系数据库在发出ALTER数据库命令时就知道如何保存数据,而同步工具(如SQL Compare)知道在SQL Server无法进行数据保存时有很多技巧。但是,总有一段时间,由于不确定性太大,因此变得不可能。此时,您需要使用T-SQL脚本将其拼写出来,但是您可以这样做。
我将描述的技术只能与“静态数据”一起使用,而不会不断更新。不过,这对于开发人员数据非常有用,因此它适合许多开发和测试工作。如果您希望使用相同的技术来同步UAT,登台或生产(例如在拆分表之后),则需要通过剪切所有其他连接来“使数据库静默”,并在您进行数据动态合并时做分裂。我将在另一篇文章中解释如何执行此操作。
合并
想象一下,我们想要一些代码来确保一个表仅包含我们想要的数据,没有更多,更少。我们使用MERGE语句,以便仅执行必要的插入或删除操作。让我们举一个简单的例子,来自AdventureWorks:
SET IDENTITY_INSERT [Adventureworks2016].[HumanResources].[Department] ON;
MERGE INTO [Adventureworks2016].[HumanResources].[Department] AS target
USING (VALUES (1, 'Engineering', 'Research and Development', '2008-04-30T00:00:00'),
(2, 'Tool Design', 'Research and Development', '2008-04-30T00:00:00'),
(3, 'Sales', 'Sales and Marketing', '2008-04-30T00:00:00'),
(4, 'Marketing', 'Sales and Marketing', '2008-04-30T00:00:00'),
(5, 'Purchasing', 'Inventory Management', '2008-04-30T00:00:00'),
(6, 'Research and Development', 'Research and Development', '2008-04-30T00:00:00'),
(7, 'Production', 'Manufacturing', '2008-04-30T00:00:00'),
(8, 'Production Control', 'Manufacturing', '2008-04-30T00:00:00'),
(9, 'Human Resources', 'Executive General and Administration', '2008-04-30T00:00:00'),
(10, 'Finance', 'Executive General and Administration', '2008-04-30T00:00:00'),
(11, 'Information Services', 'Executive General and Administration', '2008-04-30T00:00:00'),
(12, 'Document Control', 'Quality Assurance', '2008-04-30T00:00:00'),
(13, 'Quality Assurance', 'Quality Assurance', '2008-04-30T00:00:00'),
(14, 'Facilities and Maintenance', 'Executive General and Administration', '2008-04-30T00:00:00'),
(15, 'Shipping and Receiving', 'Inventory Management', '2008-04-30T00:00:00'),
(16, 'Executive', 'Executive General and Administration', '2008-04-30T00:00:00')
)source(DepartmentID, Name, GroupName, ModifiedDate)
ON source.DepartmentID = target.DepartmentID
WHEN NOT MATCHED BY TARGET THEN
INSERT ( DepartmentID, Name, GroupName, ModifiedDate )
VALUES ( DepartmentID, Name, GroupName, ModifiedDate )
WHEN NOT MATCHED BY SOURCE THEN
DELETE;
SET IDENTITY_INSERT [Adventureworks2016].[HumanResources].[Department] OFF;
该语句将确保基于主键的值在每一行都有条目。对于开发工作,我们不太在乎非关键列是否不同。如果还需要确保其他列中的值相同,则需要在WHEN MATCHED短语中附加一条语句,以便在必要时更新值,例如:
([WHEN MATCHED [AND <clause_search_condition>] THEN <merge_matched> ] [...n])
您真的要为数据库中的所有表手工编写这样的代码吗?不见得。这是PPP的输出,称为#SaveMergeStatementFromTable,我将在后面显示:
DECLARE @TheStatement NVARCHAR(MAX)
EXECUTE #SaveMergeStatementFromTable
@tablespec='Adventureworks2016.[HumanResources].[Department]',
@Statement=@TheStatement OUTPUT;
PRINT @TheStatement
它使用语句创建数据源,MERGE从您在中指定的表中创建脚本。它返回此脚本作为输出变量。然后您可以执行它。这将确保在关键字段中具有正确值的行数正确。这是一个完整而美妙的解决方案吗?不完全的。它适用于小型表,但是multi-row 子句的伸缩性不好。最好将其分解为较小的语句。对于较大的表,最终将达到需要的大小,然后使用本机BCP将数据导入到表中。如果您希望执行,则可以将数据BCP到临时表中,对其进行良好索引,然后将其用作的源,而不是使用a@tablespecVALUESVALUESTRUNCATEMERGEMERGE表值构造器。
您还可以从文件或脚本中保存JSON,并将其用作表源。对于本文,我将坚持简单性,并演示使用多行VALUES语句的原理,这些语句可以轻松地保留在源代码控制中以构建开发数据库或添加静态数据。
创建MERGE语句的数据集
有不同的方法可以做到这一点。一种是使用来自SSMS的SQL。为此,您只需要对文件系统中为此类活动保留的部分进行读写访问。对于该演示,我创建了一个目录' c:\ data \ RawData ',并授予了SQL Server访问权限。您还需要暂时允许使用xp_cmdshell。对于那些神经质的人,有时我还将提供一个可以代替使用的PowerShell脚本。
出于怀旧之情,我们将在古老的NorthWind数据库上进行尝试,因为它甚至不会给微薄的文件系统带来负担。该脚本将执行#SaveMergeStatementFromTablePPP(因此,您首先需要创建PPP;请参阅后面的内容),并依次提供每个表的名称作为源。对于sp_msforeachtable(和sp_msforeachdb)系统过程,SQL Server在表或数据库的名称中替换?您作为参数提供的字符串中的占位符(' ')。PPP会MERGE在每种情况下(@CreatedScript)生成相应的语句。对于每个表,我们使用其MERGE语句填充临时表(##myTemp),然后将其写到指定目录中的自己的文件中(不要错过路径中的尾随反冲):
USE northwind
DECLARE @ourPath sysname ='C:\data\RawData\Northwind\MergeData\';
DECLARE @TheServer sysname =@@ServerName
Declare @command NVARCHAR(4000)= '
print ''Creating SQL Merge file for ?''
DECLARE @CreatedScript NVARCHAR(MAX)
EXECUTE #SaveMergeStatementFromTable @TableSpec=''?'', @Statement=@CreatedScript OUTPUT
CREATE TABLE ##myTemp (Bulkcol nvarchar(MAX))
INSERT INTO ##myTemp (Bulkcol) SELECT @CreatedScript
print ''Writing out ?''
EXECUTE xp_cmdshell ''bcp ##myTemp out '+@ourPath+'?.SQL -c -C 65001 -T -S '+@TheServer+' ''
DROP TABLE ##myTemp'
EXECUTE sp_msforeachtable @command
GO
如果成功,它将给出以下信息:
如果要使用SQL Compare或SCA将这种数据部署合并到架构同步中,我们将只需要一个脚本。我们还需要在开始时禁用约束,并在完成后全部启用它们。这需要对该方法进行非常小的修改,但是原理保持不变。
USE northwind
DECLARE @TotalScript NVARCHAR(MAX)
DECLARE @DestinationDatabase sysname='WestWind'
DECLARE @ourPath sysname ='C:\data\RawData\Northwind\MergeData\TotalFile.sql';
DECLARE @TheServer sysname =@@ServerName
DROP TABLE IF exists ##myTemp
CREATE TABLE ##myTemp (Bulkcol nvarchar(MAX))
DECLARE @DisableConstraints nvarchar(4000)='Print ''Disabling all table constraints''
'
SELECT @DisableConstraints=@DisableConstraints+'ALTER TABLE [WestWind].[dbo].'+QuoteName(name)+' NOCHECK CONSTRAINT ALL
' FROM sys.tables
INSERT INTO ##myTemp (BulkCol) SELECT @DisableConstraints
DECLARE @command NVARCHAR(4000)= '
print ''Creating SQL Merge file for ?''
DECLARE @CreatedScript NVARCHAR(MAX)
EXECUTE #SaveMergeStatementFromTable @TableSpec=''?'',@DestinationDatabase='''+@DestinationDatabase+''',@Statement=@CreatedScript OUTPUT
INSERT INTO ##myTemp (Bulkcol) SELECT coalesce(@CreatedScript,'''')+''
''
'
SELECT @command
EXECUTE sp_msforeachtable @command
print 'Writing out file'
DECLARE @BCPCommand NVARCHAR(4000)='bcp ##myTemp out '+@ourPath+' -c -C 65001 -T -S '+@TheServer
EXECUTE xp_cmdshell @BCPCommand
DECLARE @endCommand VARCHAR(4000)= (SELECT 'ECHO EXEC sp_msforeachtable ''ALTER TABLE ? WITH CHECK CHECK CONSTRAINT all'' >>'+@ourPath)
EXECUTE xp_cmdshell @endCommand
DROP TABLE ##myTemp
奇怪的是,当SQL Compare执行synch脚本时,如果您不小心,它可能会为在SSMS中执行脚本时能正常工作的代码提出错误。这解释了为什么逐表禁用约束。这也解释了为什么我避免使用GO批量定界符。
这将产生一个文件...
如果直接在SSMS中执行此文件,它将检查每个表并进行必要的插入和删除操作,以确保数据相同。当添加到同步脚本后,它将对您创建或更改的数据库执行相同的操作。
如果您希望使用其他名称部署到数据库,则可以将@DestinationDatabase可选参数设置为#SaveMergeStatementFromTable正在创建或同步的数据库的名称,正如我在前面的代码中所演示的那样。如果我需要一个依赖于先前脚本的脚本来提供数据库上下文(SQL Compare和SCA会执行此操作),则可以通过将@DontSpecifyTheDatabase可选参数设置为1 来隐藏三部分名称的数据库部分。
现在我们有了文件,可以将其放入“源代码管理”中。好的,我在这里是假装的,因为我没有开发Northwind。我要做的就是通过使用SQL Compare将Northwind数据库与空目录进行比较来创建源代码管理目录。然后,我已经添加了自定义脚本目录及其部署后和部署前的子目录。
使用真实的数据库,MERGE只要修改表,就可以非常简单地运行SQL来生成语句。合并语句依赖于它们作用于具有相同名称的相同列数的表。如果不是,将出现错误。如果您修改源脚本中的表,以使目标数据库中的一个或多个表不同,则相应的同步后合并语句将需要符合新设计。
现在,我将合并脚本(TotalFile.sql)放入Post-Deployment目录中。一旦开发了此技术,则可以通过指定适当的部署后目录的正确路径,通过SQL Batch文件或PowerShell脚本直接将文件写入。
从那时起,我可以使用此目录同步数据和架构。SQL Compare会将脚本追加到它生成的生成脚本的末尾,并使用它来填充表。请注意,在数据填充操作之前禁用约束并在之后启用约束很重要。如果您有意在源代码管理的对象构建脚本中禁用了约束,则可能导致问题,但是我们将忽略该问题。
强大的程序
我使用了临时过程来完成创建MERGE脚本中的驴工作。这是我用来提取数据的一系列过程中的一个,我在https://github.com/Phil-Factor/JSONSQLServerRoutines上维护这些过程。
如果指定表,则此PPP将创建一条MERGE语句。它必须在SQL Server 2017或更高版本上运行,因为它使用了该STRING_AGG功能。如果使用XML串联技巧,可以将其更改为在SQL Server 2016上运行。
它使用VALUES包含表中数据的多行语句创建表源,并将其用作MERGE语句源,然后可以在提供其名称的目标表上执行该语句。如所讨论的,该技术仅对小表才可行,因为使用该VALUES子句意味着该子句随比例降低。
源表或查询可以通过的' database.schema.table'格式指定@tablespec,也可以通过分别提供表名称,模式和数据库来指定。您可以提供查询,尽管在这种情况下,您将需要提供目标表的名称。您的查询将提供源数据,并且必须以正确的顺序为您指定的目标表生成正确的表源,并以正确的顺序显示正确的列。
完善系统
除了表名,您还可以向该例程提供查询。该查询必须产生与目标表相同的结果,当然不包括计算列。这有效地使您可以指定例如如何填充表拆分的结果表。通常,MERGE我们通过传递给过程的表来确定主键。但是,查询结果不能有主键。您可以通过两种方法解决此问题。
首先,您可以填充已填充了所需测试数据的临时表,然后添加主键。我们通过使用临时表作为源的查询将临时表中的数据传递给过程:
USE AdventureWorks2016;
SELECT TOP 100 Customer.PersonID, AccountNumber,
Identity(INT, 1, 1) AS uniquifier, PersonType, Title, FirstName, MiddleName,
LastName, Suffix, AddressLine1, AddressLine2, City, PostalCode, Name
INTO #tempTable
FROM Sales.Customer
INNER JOIN Person.Person
ON Customer.PersonID = Person.BusinessEntityID
INNER JOIN Person.BusinessEntityAddress
ON Person.BusinessEntityID = BusinessEntityAddress.BusinessEntityID
INNER JOIN Person.Address
ON BusinessEntityAddress.AddressID = Address.AddressID
INNER JOIN Person.AddressType
ON BusinessEntityAddress.AddressTypeID = AddressType.AddressTypeID;
ALTER TABLE #tempTable ALTER COLUMN PersonID INTEGER NOT NULL;
ALTER TABLE #tempTable
ADD CONSTRAINT MyTempPKConstraint PRIMARY KEY CLUSTERED
(PersonID, AccountNumber, uniquifier);
DECLARE @TheStatement NVARCHAR(MAX);
EXECUTE #SaveMergeStatementFromTable @Query = 'Select top 100 * from #tempTable',
@Destination = 'MyTempTable', @Statement = @TheStatement OUTPUT;
PRINT @TheStatement;
DROP TABLE #tempTable;
或者,您可以根据需要指定要使用的主键。
USE AdventureWorks2016;
DECLARE @TheStatement NVARCHAR(MAX);
EXECUTE #SaveMergeStatementFromTable
@Query = '
SELECT top 10 Customer.PersonID, AccountNumber,
PersonType, Title, FirstName, MiddleName,
LastName, Suffix, AddressLine1, AddressLine2, City, PostalCode, Name
FROM Sales.Customer
INNER JOIN Person.Person
ON Customer.PersonID = Person.BusinessEntityID
INNER JOIN Person.BusinessEntityAddress
ON Person.BusinessEntityID = BusinessEntityAddress.BusinessEntityID
INNER JOIN Person.Address
ON BusinessEntityAddress.AddressID = Address.AddressID
INNER JOIN Person.AddressType
ON BusinessEntityAddress.AddressTypeID = AddressType.AddressTypeID',
@Destination = 'MyTempTable',
@PrimaryKeys='PersonID, AccountNumber',
@Statement = @TheStatement OUTPUT;
PRINT @TheStatement;
结论
进行SQL比较并发现数据和架构与源数据库相同是令人惊讶的。如果数据库中的表设计发生更改,则只需要准备一个新的部署后脚本,但是由于它都是自动进行的,因此我认为这反倒不会带来太大麻烦。我使用多行VALUES语句是因为它看起来比使用JSON来保存数据要少一些,但是我认为使用JSON可以允许使用更大的表。
为什么不只使用本地BCP来存储表?按照我在此处演示的方法进行操作,意味着普通的SQL Compare或SCA部署可以完成此操作而无需其他脚本。一切都由数据库脚本保存。
相关产品推荐:
SQL Prompt:SQL语法提示工具
SQL Toolbelt:Red Gate产品套包
SQL Monitor:SQL Server监控工具

标签:
本站文章除注明转载外,均为本站原创或翻译。欢迎任何形式的转载,但请务必注明出处、不得修改原文相关链接,如果存在内容上的异议请邮件反馈至chenjj@evget.com
文章转载自:Red Gate


 首页
首页 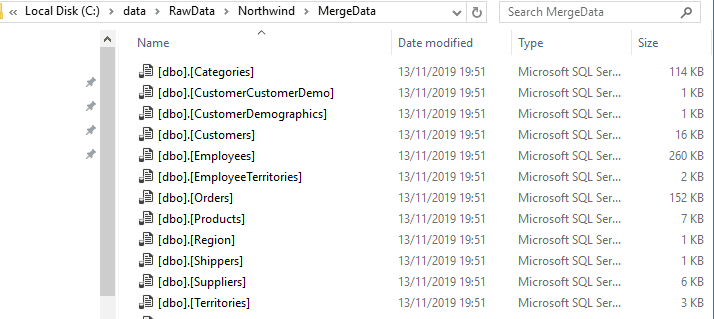














 7次
7次


 相关产品
相关产品 最新文章
最新文章 
 相关文章
相关文章 
 微信
微信 在线咨询
在线咨询




 渝公网安备
50010702500608号
渝公网安备
50010702500608号

 客服热线
客服热线