要想在Qlik中开始学习机器学习,你需要对脚本和数据建模有一些基本的了解。总的来说,如果你已经开发QlikView或Qlik Sense应用程序好几年了(我指的是从头开始开发,而不仅仅是表达式和界面设计),脚本不会超级复杂。然而,你不需要任何统计学或机器学习方面的知识就能理解其中的大部分内容。如果你想进一步了解为什么代码能用,你肯定需要一些数学技能和一点统计学知识。

机器学习和人工智能?
尽管关于机器学习和人工智能的文章已经有上千篇,但我还是先分享一下这些学科的高大上图景。人工智能可以分为三个方面。
-
人工狭义智能:又称弱AI,是 "目标导向",解决单一给定任务。它是目前唯一的人工智能。
-
人工通用智能:能够解决 "任何 "任务。但是一些科学家质疑人工通用智能是否会真正存在,是否需要我们花20年或1000年的时间才能达到。
-
人工超级智能:这是一种远远超出了人类的智慧的人工智能。
机器学习
机器学习是人工狭义智能的主要领域之一。其他分支还有虚拟助手和专家系统。开发通过经验自动改进的计算机算法的理论思想可以追溯到现代历史。早在1950年就有了第一个想法,但真正的推动是在20年前,当计算机的能力和廉价程度足以运行这些算法并取得良好效果时,才有了真正的推动。然而,随着计算机的速度越来越快,数据量也在增加。在处理海量信息时,不可能单独看待每个数据点,所以需要一种新的方法。深度学习在某种程度上就是--大数据的机器学习。其他算法,如人工神经网络,试图模拟我们的大脑如何工作。
机器学习可以分为三个领域:
该算法是用已经有结果的数据进行 "训练 "的。训练完成后,我们可以用它对独立的数据集进行 "预测 "结果。
其本身分为两组:
-
回归: 预测给定样本的结果,输出是实值的形式。举例来说。根据树的类型和大小来预测树上鸟的数量。
-
分类法:预测给定样本的结果,输出为实值形式。预测给定样本的结果,其输出是以类别的形式。预测一个病人是否有患糖尿病的风险(是/否)。
例如:线性回归、逻辑回归、CART、奈夫贝叶斯、KNN、随机森林都是监督学习算法的例子。
无监督学习的目的不是为了预测结果。而是用来寻找数据中的相似性和模式。在使用监督学习对数据进行 "清洗 "和 "分类 "之前,它经常被用作一个步骤。换句话说,它确保你只使用与算法相关的数据。
无监督学习分为三种类型:
-
联想:计算一个数据的概率 计算一个数据点与另一个数据点共存的概率。一个流行的例子是篮子分析。如果一个顾客购买了一件雨衣,他有80%的可能性也会购买一把伞。
-
聚类:根据数据点的相似度,将数据点进行聚类。
-
维度降低:减少数据点的数量。减少数据集中的变量数量,同时确保重要信息仍能传达。删除与选定目的无关的特征。这些算法是特征工程工作中的好助手。
例如:Apriori、K-means Apriori,K-means和PCA。
-
强化学习
-
在强化学习中,算法不断地被输入新的信息。在做新的预测时,它也会考虑到自己预测的结果。
例如:交通灯控制系统和电脑游戏中的代理。
Qlik+机器学习系列
这篇文章将涵盖一些最流行的机器学习算法,从线性/逻辑回归和决策树到深度学习和人工神经网络。
例子: 使用线性梯度下降法
任务:根据索赔数量预测保险索赔金额。
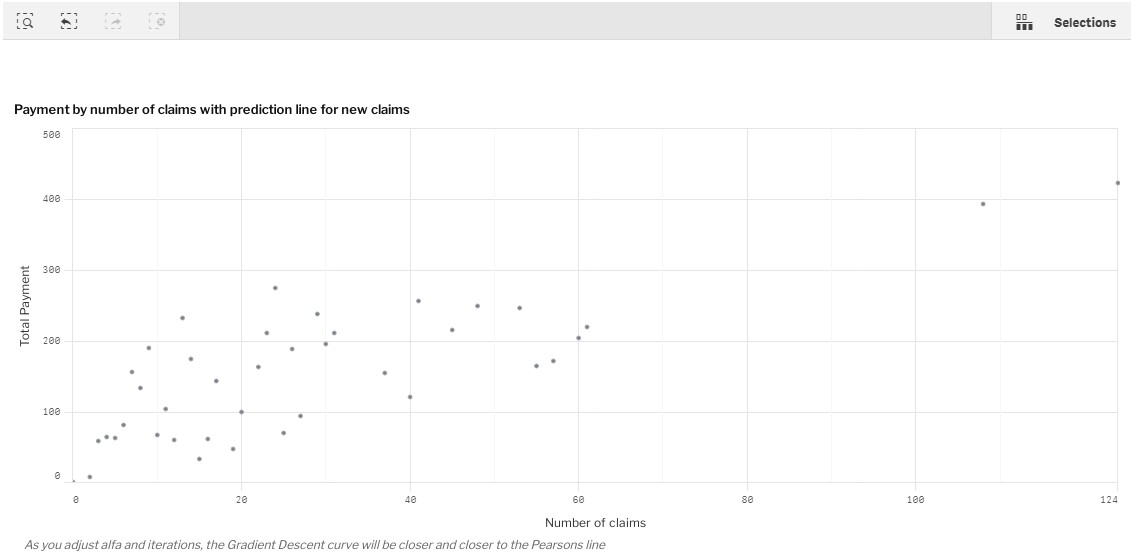
该图表包含有关虚拟汽车保险公司的数据。它按“索赔数量”显示“总付款额”。每个点代表一段时间,例如几个月或几年。
数据来源:瑞典的汽车保险 (在此下载数据)。
数据提取(前10行):
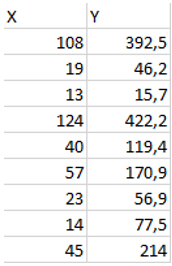
X = 保险索赔数量
Y=所有保险索赔的总付款额,单位为千瑞典克朗。
在这种情况下,保险公司希望预测他们将为当月收到的索赔支付多少钱。让我们假设在上一个时期,他们总共收到了36起索赔。他们应该为这些索赔保留多少钱?
线性梯度下降算法的目标是找出一条直线的公式,以最好的方式拟合所有的数据点。

手动预测
没有什么比用数据做实验更好的了! 这里是一个Qlik Sense的可视化,你可以尝试通过拖动两个滑动条来调整线条。
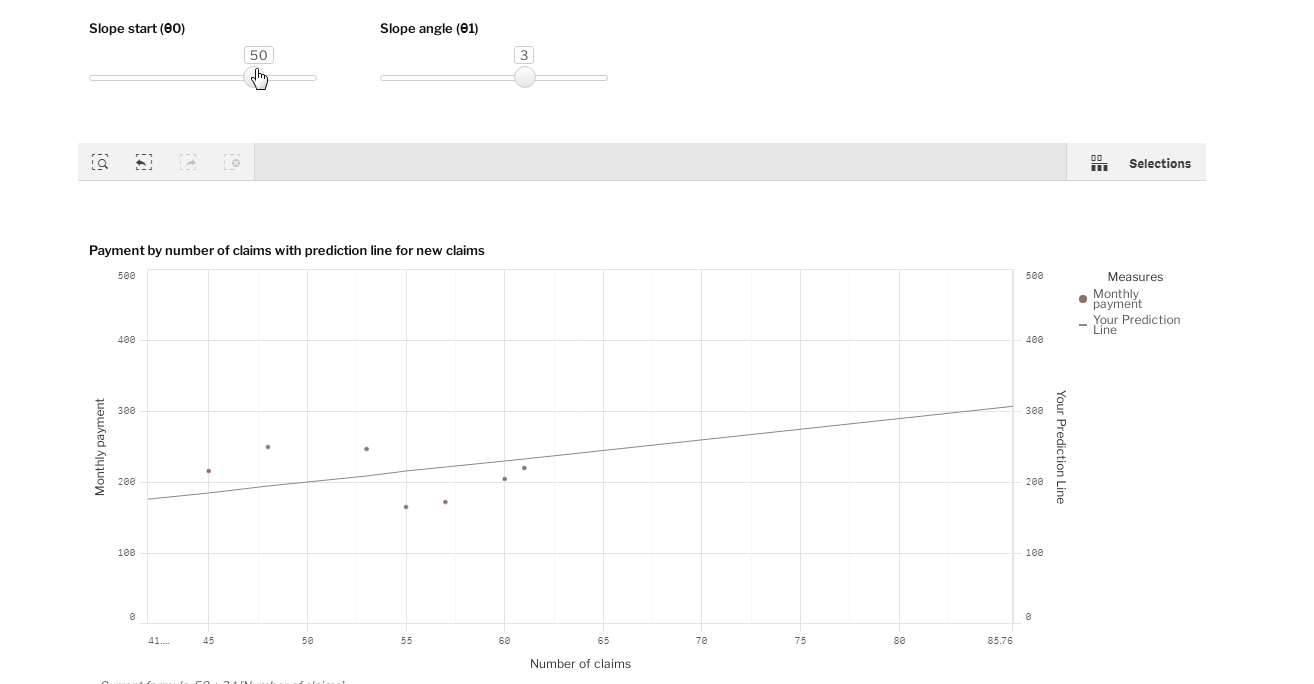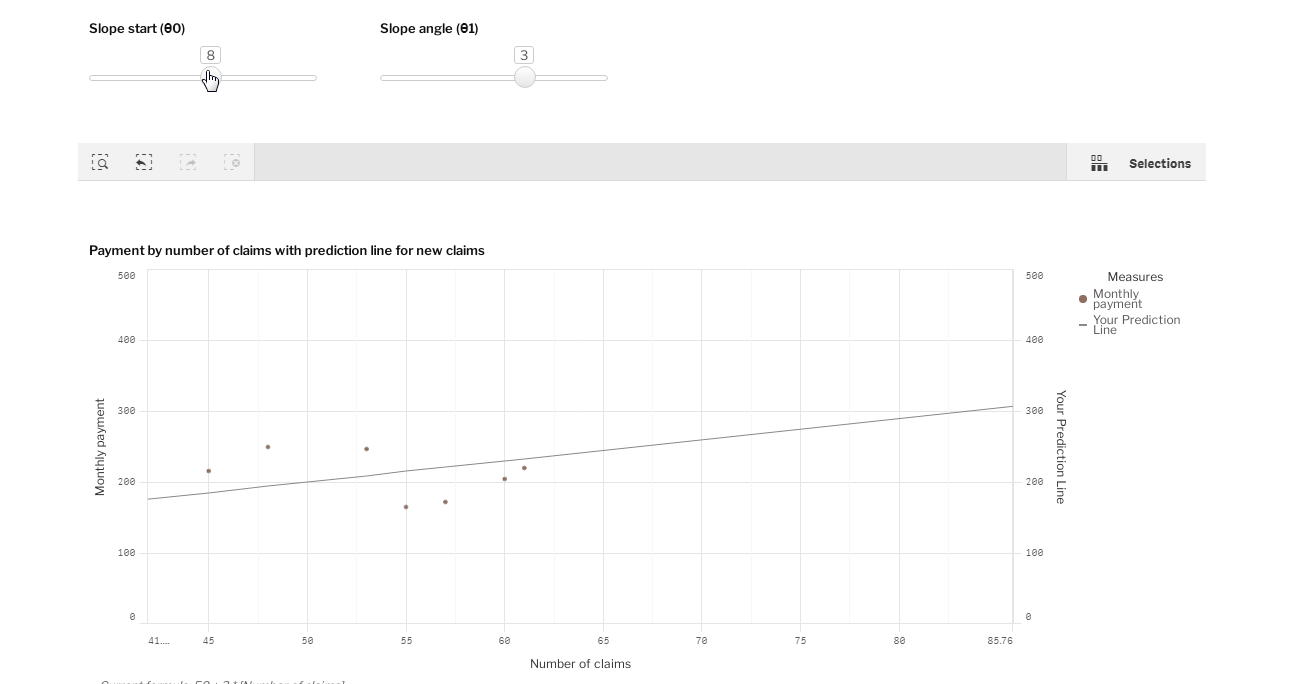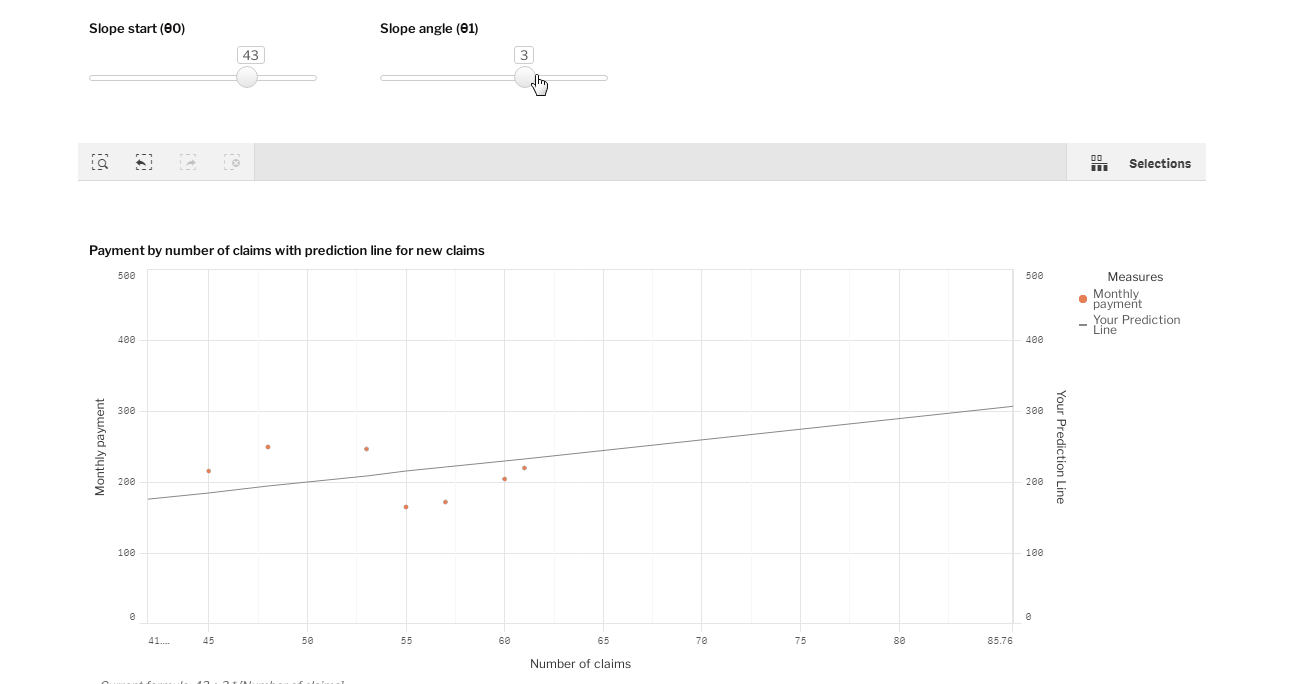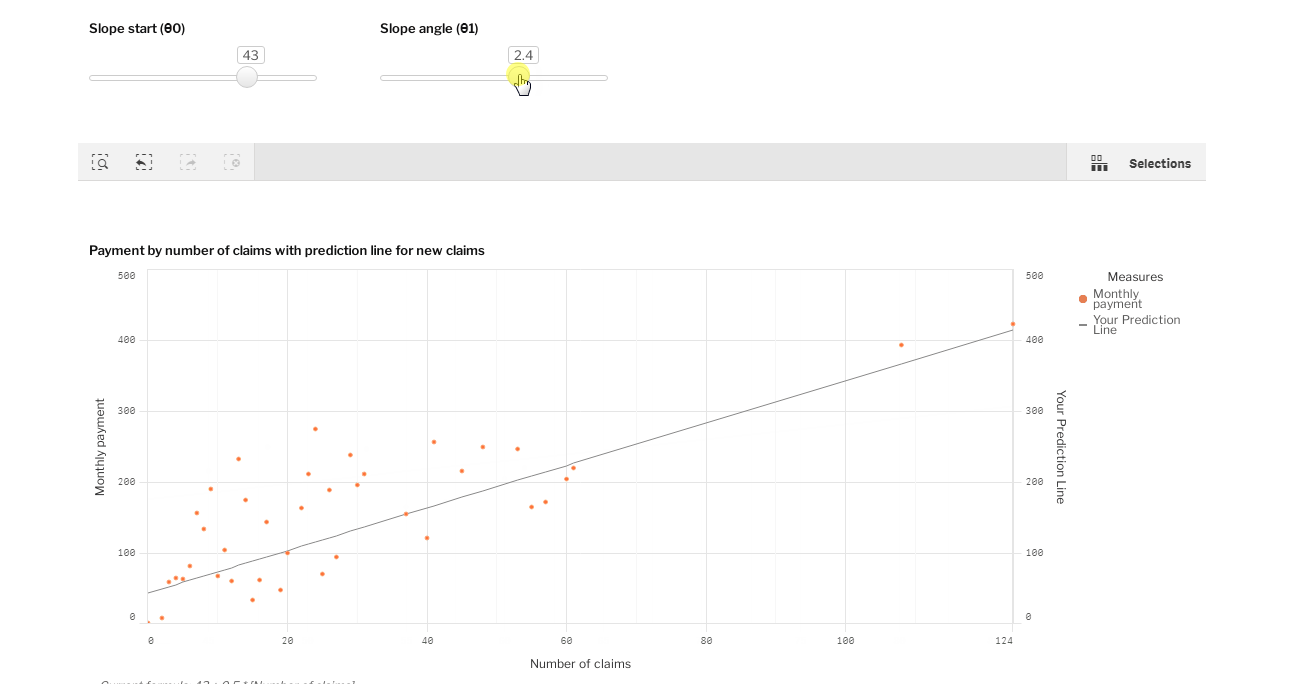
调整[斜率起点(θ0)]和[斜率角(θ1)]的值,并尝试做出一条符合所有点的线。然后,在你的预测线的帮助下,回答问题。"保险公司应该为36次索赔准备多少钱?"
正确的答案是什么?
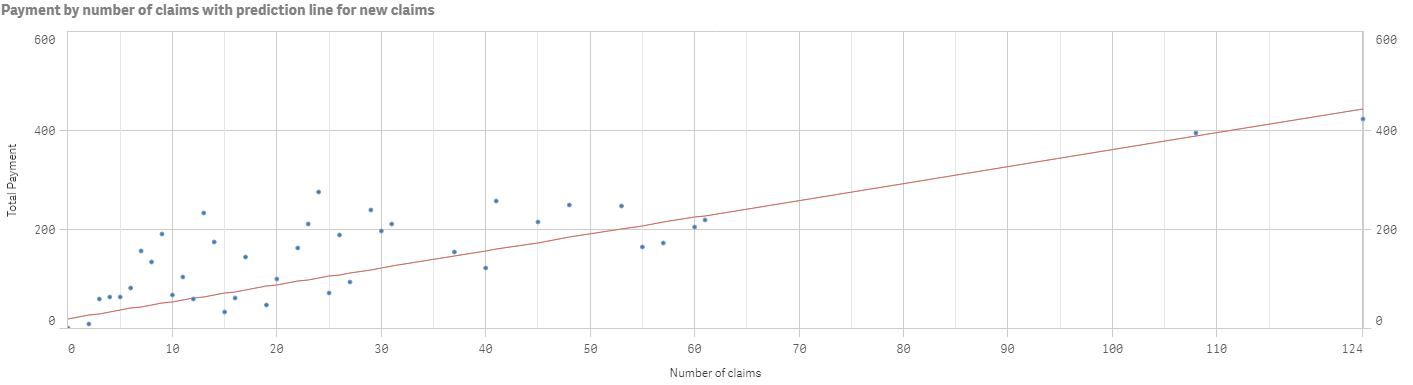
本图中的红线是梯度下降算法的结果。它得出了以下结论:
-
坡度起点(θ0)=19.79
-
坡度角(θ1)=3.42
也许你还记得上学时直线的方程:y=kx+m。用这个方程代替即可。"付款预测"="坡度起点(θ0)" +"斜角(θ1)" * "索赔数量"。答案是:"19.79 + 3.42 * 36 ~ 142 SEK"。
但是,这是正确的答案吗?其实在机器学习中,没有 "正确的答案"。这些算法通常会给你一个 "相当OK "的数字!它需要 "训练 "更多的数据。 它要 "训练 "的数据越多,预测的效果就越好。做好预测的关键是了解使用哪种算法,当然,线性梯度下降并不总是最好的选择!
直线很少能完美地拟合你的数据,但它比胡乱猜测要好得多。然而,做一条符合所有点的曲线也不是一个好主意,这叫做过度拟合。
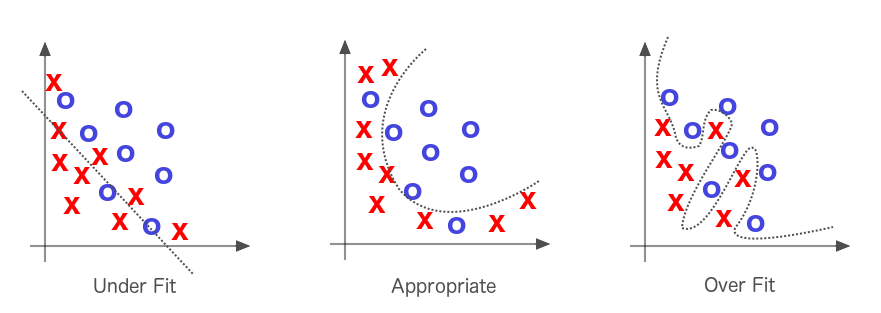
如果你熟悉统计学,你可以使用简单的线性回归来建立预测线。但是,如果你的数据中的列数增加,你将不得不使用大量的 "昂贵的数学 "来建立预测(效果很好,但需要大量的计算机能力)。这就是机器学习算法的用武之地。梯度分解算法不会随着列数的增加而变得越来越复杂。对于较大的数据集来说,它是一个廉价而快速的选择!
脚本样本
在Qlik Sense中实现一个简单的梯度下降算法并不难,也不需要实现Python!!
// LOAD TRAINING DATA
Training_table:
LOAD
num(num#(X,'',',')) as X,
num(num#(Y,'',',')) as Y
FROM [lib://AI_DATA/INSURANCE/data.txt]
(txt, codepage is 28591, embedded labels, delimiter is '\t', msq);
// GRADIENT DESCENT FUNCTION
// DEFINE HOW MANY TIMES TO LOOP
Let iterations= 15000;
// DEFINE LEARNING RATE
Let α = 0.001;
// DEFINE START VALUES FOR ALL THETAS (WEIGHTS).
Let θ0 = 0;Let θ1 = 0;
// GET HOW MANY ROWS TRAINING DATA HAS.
Let m = NoOfRows('Training_table');
// START LOOP
For i = 1 to iterations
// CREATE A SUMMARY TEMP TABLE
temp:
LOAD
Rangesum(($(θ0) + (X* $(θ1)) - Y),
peek(deviation_0)) as deviation_0,
Rangesum(($(θ0) + (X * $(θ1)) - Y) * X,
peek(deviation_X)) as deviation_X
Resident Training_table;
// GET THE LAST ROW FROM THE temp TABLE
// THAT HAS THE TOTAL SUM OF ALL ROWS
Let deviation_0 = Peek('deviation_0',-1,'temp');
Let deviation_X = Peek('deviation_X',-1,'temp');
// DROP THE temp TABLE. NO LONGER NEEDED
drop table temp;
// CHANGE THE VALUE OF EACH θ TOWARDS A BETTER θ
Let θ0 = θ0 - ( α * 1/m * deviation_0);
Let θ1 = θ1 - ( α * 1/m * deviation_X);
// REPEAT UNTIL ITERATIONS HAVE REACHED THE GIVEN MAX
next i;
点击获取Qlik
关于Qlik
Qlik的愿景是一个数据素养的世界,每个人都可以使用数据来改善决策并解决他们最具挑战性的问题。只有Qlik提供端到端的实时数据集成和分析解决方案,以帮助组织访问所有数据并将其转化为价值。慧都作为Qlik官方的中国合作伙伴,我们为Qlik的中国用户提供产品授权与实施、定制分析方案、技术培训等服务,旨在让中国企业的每个Qlik用户都能探索出数据的价值,让企业形成分析文化。了解更多信息,请咨询在线客服>>
标签:
本站文章除注明转载外,均为本站原创或翻译。欢迎任何形式的转载,但请务必注明出处、不得修改原文相关链接,如果存在内容上的异议请邮件反馈至chenjj@evget.com


 首页
首页 









 282次
282次


 相关产品
相关产品 最新文章
最新文章 
 相关文章
相关文章 


 微信
微信 在线咨询
在线咨询




 渝公网安备
50010702500608号
渝公网安备
50010702500608号

 客服热线
客服热线